
Generating realistic images from arbitrary views based on a single source image remains a significant challenge in computer vision, with broad applications ranging from e-commerce to immersive virtual experiences. Recent advancements in diffusion models, particularly the Zero-1-to-3 model, have been widely adopted for generating plausible views, videos, and 3D models. However, these models still struggle with inconsistencies and implausibility in new views generation, especially for challenging changes in viewpoint. In this work, we propose Zero-to-Hero, a novel test-time approach that enhances view synthesis by manipulating attention maps during the denoising process of Zero-1-to-3. By drawing an analogy between the denoising process and stochastic gradient descent (SGD), we implement a filtering mechanism that aggregates attention maps, enhancing generation reliability and authenticity. This process improves geometric consistency without requiring retraining or significant computational resources. Additionally, we modify the self-attention mechanism to integrate information from the source view, reducing shape distortions. These processes are further supported by a specialized sampling schedule. Experimental results demonstrate substantial improvements in fidelity and consistency, validated on a diverse set of out-of-distribution objects.
Attention layers are critical in shaping the structure and appearance of generated images. Noise present in the latent induces attention map noise that accumulates throughout the denoising process, resulting in visual artifacts.
Which Attention Maps Should we Denoise? (Spoiler: Self-Attention).
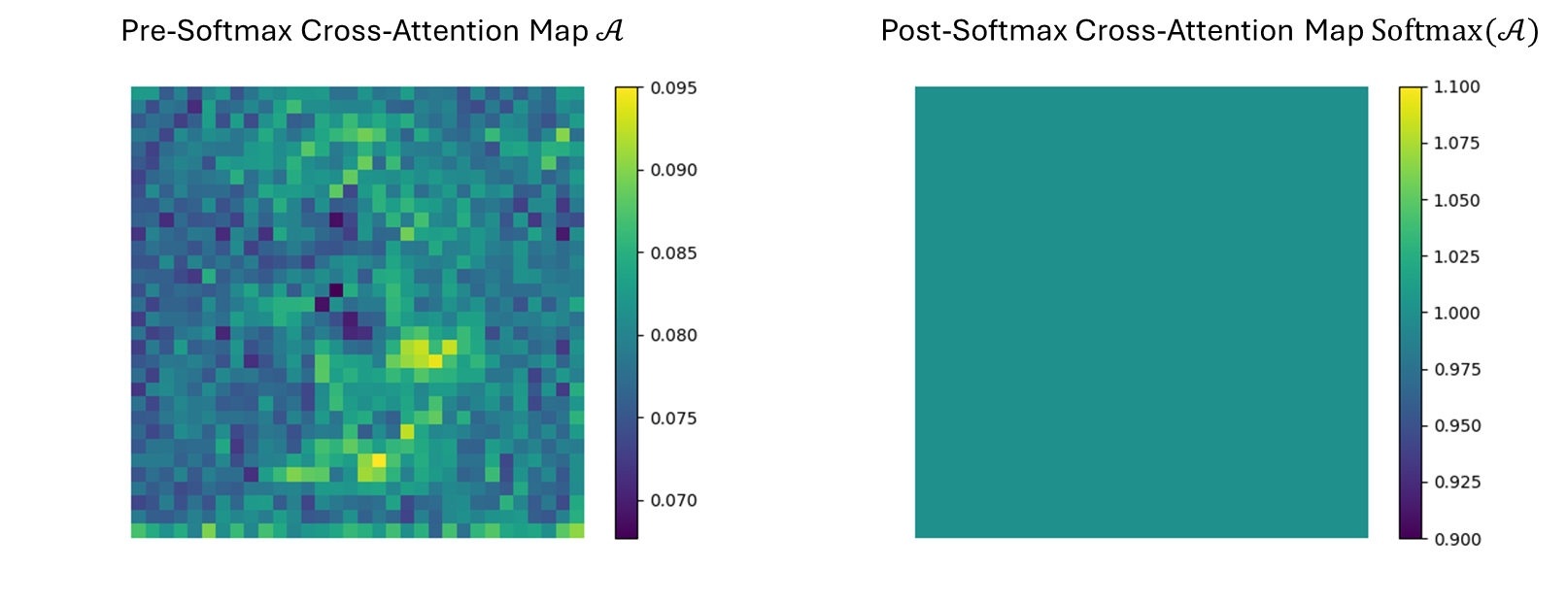
The single embedding condition in the cross-attention of Zero-1-to-3 results in a single key-value pair. Consequently, the Softmax degenerates the scores to an all-ones matrix, losing spatial awareness.
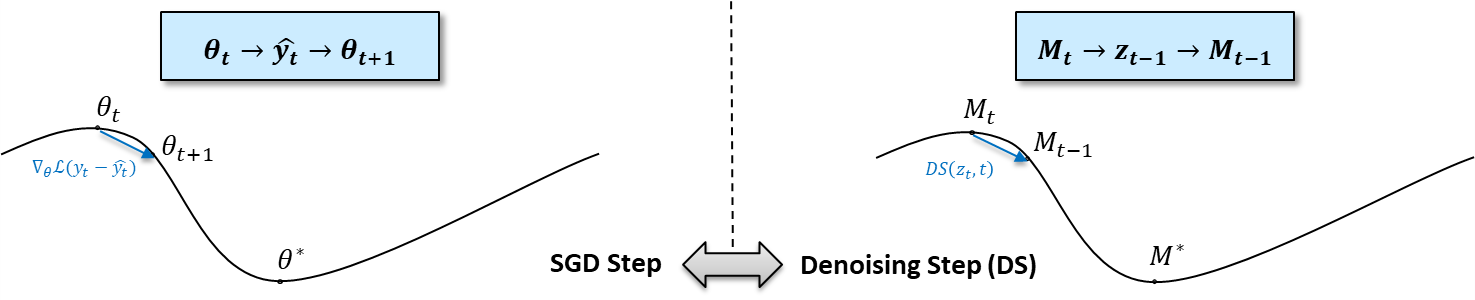
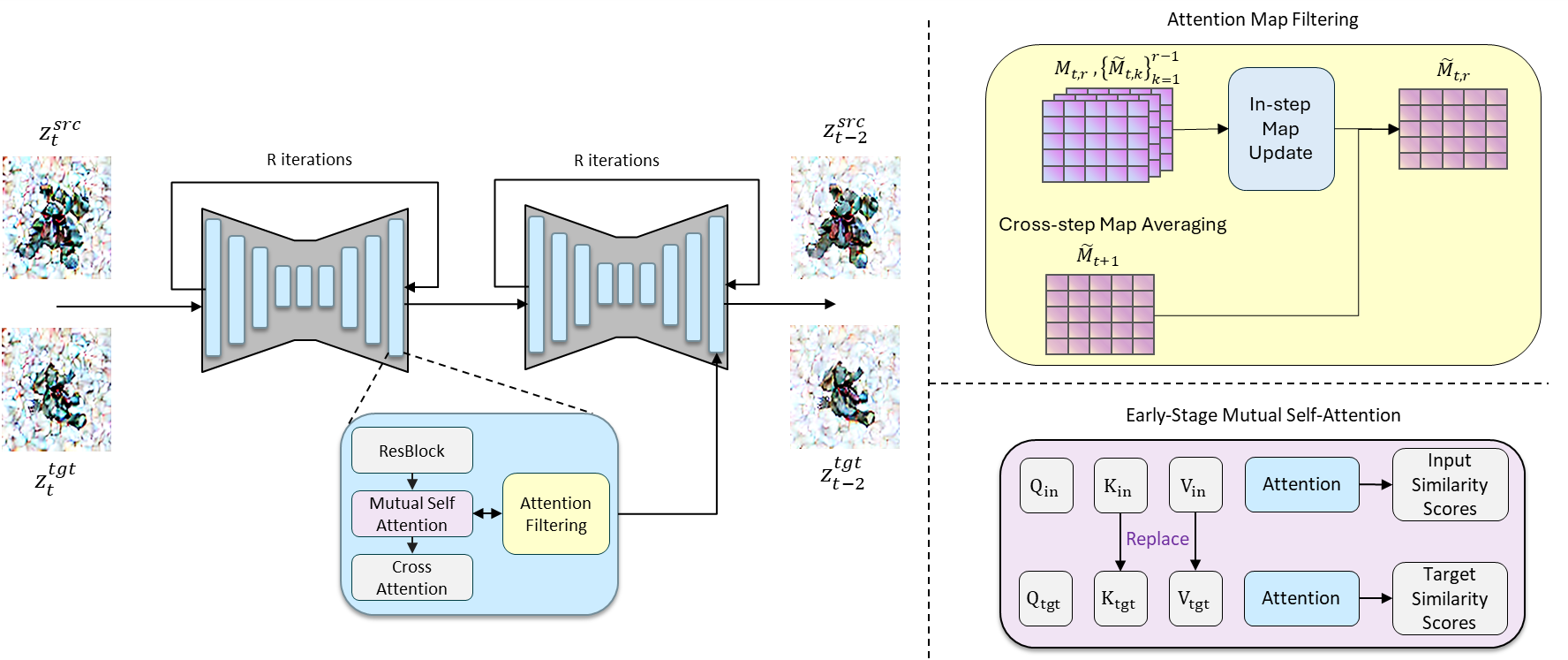
Robustifying attention maps can reduce generation artifacts. Inspired by gradient aggregation and weight averaging in SGD, we view the denoising as an unrolled optimization, with attention maps as parameters in a score prediction model.
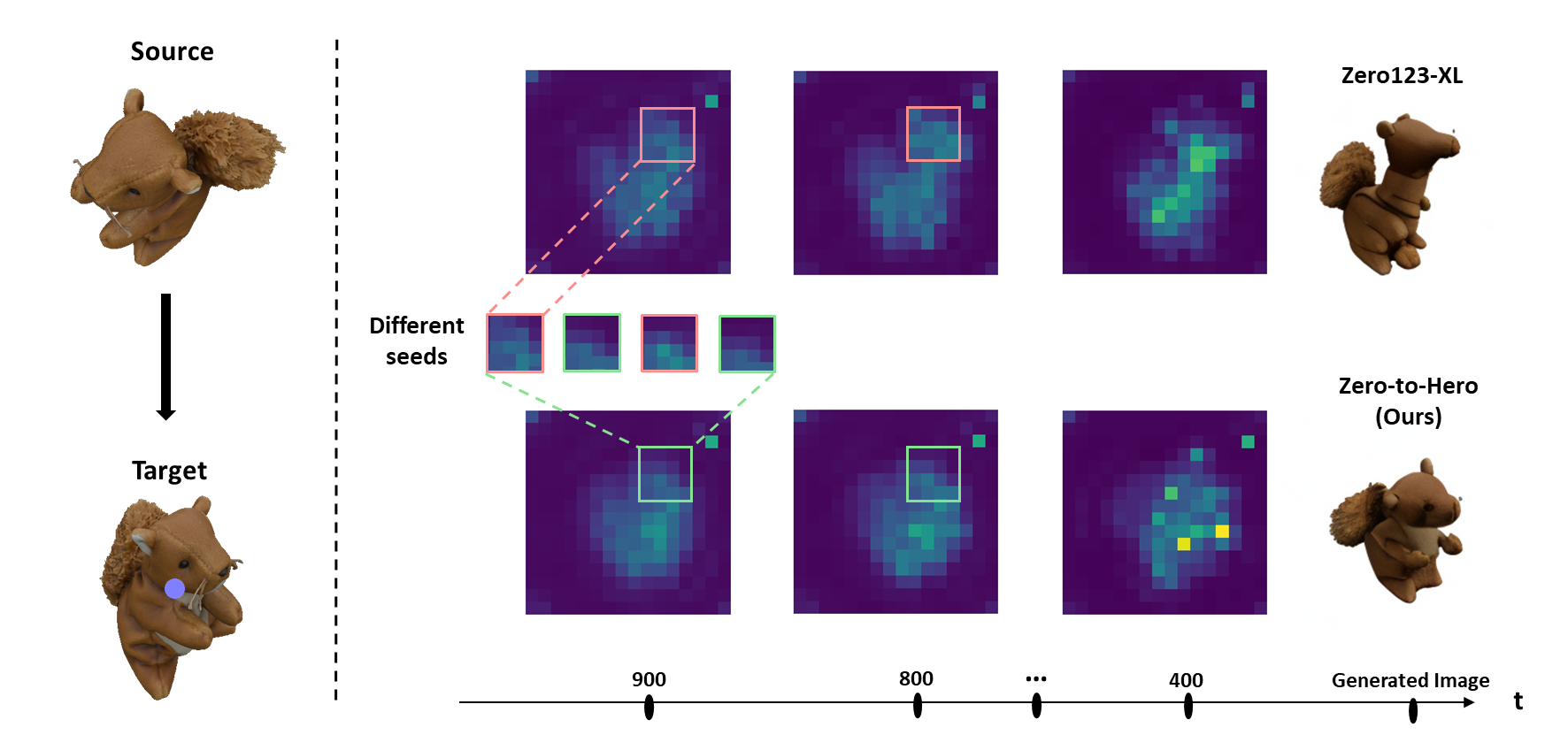
We collect a set of attention maps for each timestep through resampling, then aggregate the maps both within and across timesteps to refine the predictions. This process is training-free, resulting in more accurate maps and a more faithful generation.
Using "Mutual Self-Attention" during early stages of denoising, we propagate information from the input to the generated view. Our entire pipeline is shown in the figure.
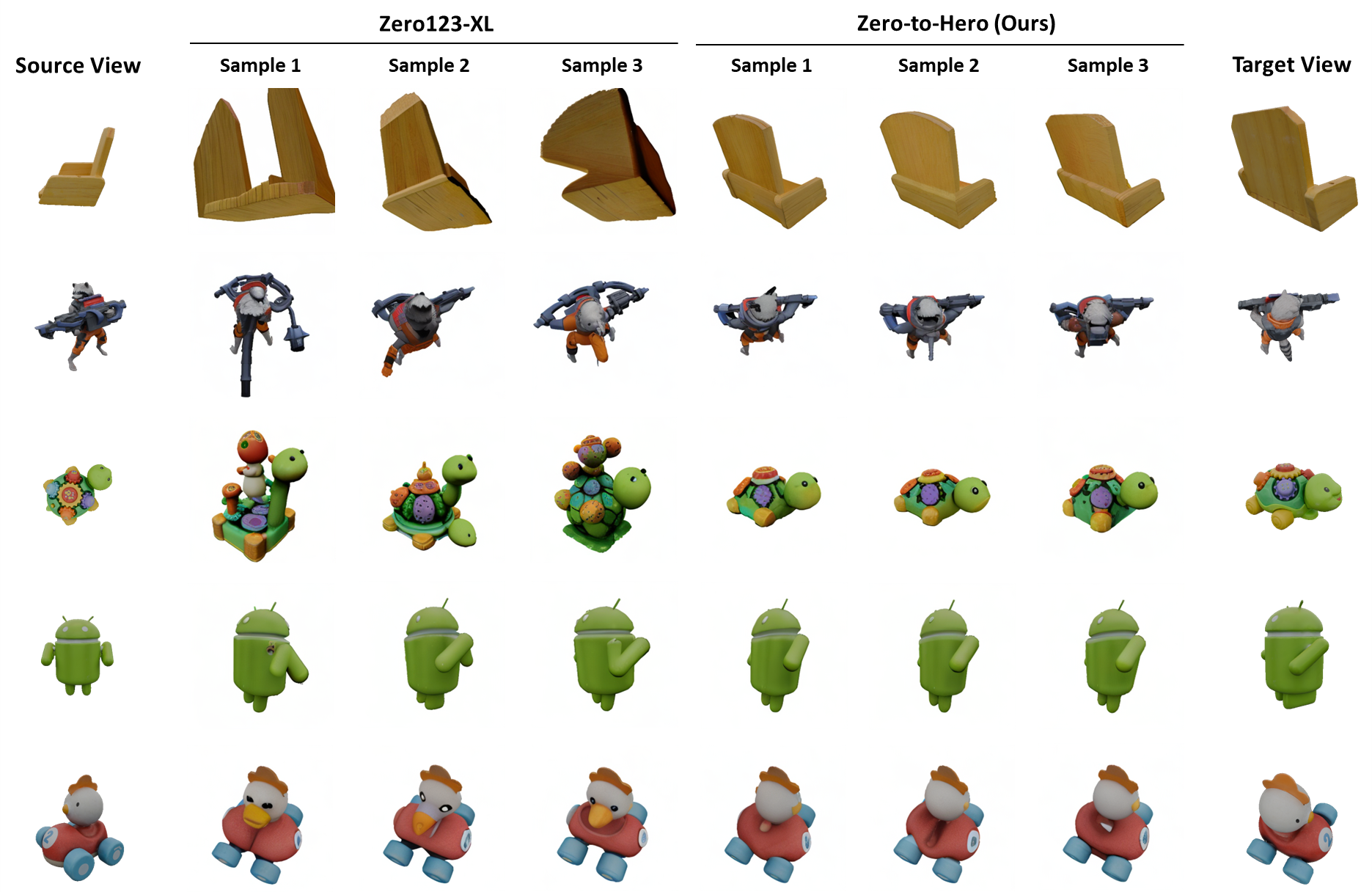
We implemented Zero-to-Hero on three tasks: image generation conditioned on (1) pose and (2) segmentation maps, as well as (3) multiview generation. In all cases we achieve a significant performance boost.

@article{sobol2024zero2hero,
author={Ido Sobol and Chenfeng Xu and Or Litany},
title = {Zero-to-Hero: Enhancing Zero-Shot Novel View Synthesis via Attention Map Filtering},
journal = {NeurIPS},
year = {2024},
}